
Veri Görselleştirme Nedir?
Günümüz teknolojisinin akıl almaz gelişimi sayesinde her yanımızda veri patlaması yaşanıyor. Özellikle bilimsel araştırmalarımızda anket çalışmaları ve deneysel faaliyetler sonucu, kolaylıkla veri toplayabiliyoruz. Veri görselleştirme, topladığımız bu verileri grafiksel gösterimler ile anlamlandırabileceğimiz muhteşem bir alan.
Veri görselleştirme, kısaca verilerimize uyguladığımız istatistik analiz teknikleri üzerinden anlamlı sonuçları grafiksel olarak sunma faaliyetlerinin tümünü kapsamaktadır.
Bu yazımızda verilerimizi nasıl harika görsellere dönüştürebileceğimizi göreceğiz.
Veri Görselleştirme ile İstatistiksel Analizler
Şimdi makalelerimizde yer alan istatistiksel analiz tablolarımızı bir hayal edelim. Bazen onlarca demografik faktöre ilişkin ortalama karşılaştırma testlerini tek tek yorumlamanın ne kadar yorucu…
Bir tabloda 10 demografik faktör ile 5 nicel ölçümün ortalama karşılaştırma testi sonuçları (t-testi, ANOVA) aritmetik ortalama, standart sapma, minimum-maksimum gibi tanımlayıcı istatistikler ile birleştiğinde ortaya müthiş karmaşık bir görüntü çıkıyor.
Benzer problemi yalnızca istatistik testleri için değil; faktör analizi, kümeleme analizi gibi çok değişkenli istatistiksel analiz teknikleri için de yaşıyoruz.
Hatta aykırı değer analizi, kayıp veri analizi gibi veri ön işleme aşamalarında da büyük veri yığınlarından tek tek çıkarımda bulunmak oldukça zor.
Veri ön işleme, istatistiksel hipotez testleri, çok değişkenli istatistiksel analiz teknikleri, veri madenciliği ve makine öğrenimi gibi çok geniş uygulama alanlarında veri görselleştirme teknikleri bizlere müthiş yorumlama kolaylığı sağlıyor.
Hemen örneklendirmeye başlayalım.
Örneğin; sayısal verilerimizde olası aykırı değerleri gözlemlemek istiyoruz. 102 hastanın hba1c ölçümleri ve kolestrol değerlerinin olduğu bir veri setini alalım.
İki değişken üzerinden hba1c ve kolestrol değerlerine göre olası aykırı gözlemleri teşhis etmek için R programı ile hazırladığımız bir veri görselini aşağıdaki şekilde sunuyoruz.
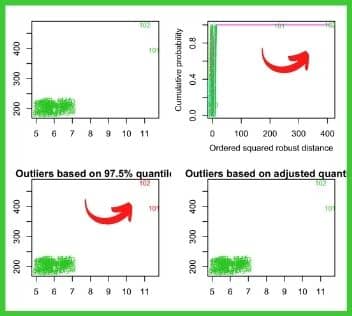
Bu görselden çok net bir şekilde, 101 ve 102. gözlemlerin aykırı değer olduğunu görebiliyoruz. Yani bu iki aykırı hastanın durumunu dikkatlice incelememiz gerekiyor! Bunlar potansiyel aykırı gözlemler.
Şimdi de kayıp verilerde görselleştirme tekniklerini nasıl kullanacağımızı görelim. Anket verilerimizde kayıp değerlerin nasıl dağıldığını bir bakışta aşağıdaki grafiğimizde görebiliyoruz.
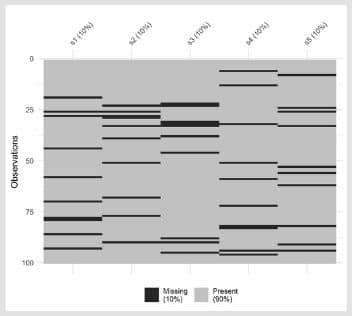
Bu grafikte beş soruya dair kayıp değerlerin siyah çizgiler ile nasıl dağıldığını, soru bazında kayıp değer oranının % kaç olduğunu kolaylıkla gözlemleyebiliyoruz. Genel verilerin bütününe bakınca, bu verilerimizde %10 düzeyinde bir kayıp verinin olduğunu da grafikten okuyabiliyoruz.
Bir bakışta kayıp verilerin hangi gözlemlerde hangi değişkenler bazında toplandığını görebilmek!
İşte bütün mesele bu…
Örnekleri biraz çoğaltalım. Aşağıda grafikte eğitim türlerine göre kaygı ölçeğinin puanlarının post-hoc çoklu karşılaştırma sonuçlarını gösteren bir görseli paylaşalım. Bu görsel de R programı ile hazırlandı.
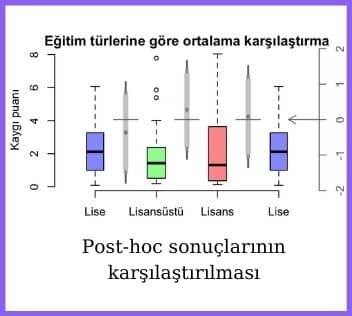
Bu grafiğe göre ikili eğitim grupları için kaygı puanları arasında istatistiksel olarak anlamlı bir farkın olmadığını rahatlıkla görebiliyoruz. Çünkü farkların güven aralıklarının her biri sıfır noktasını kapsıyor.
Bu sonucu Tukey testi ile tablo üzerinden değerlendirmek yerine muhteşem bir görsel ile değerlendirmek çok daha kolay, çok daha zevkli gözüküyor.
Şimdi de psikoloji alanında uygulanan bir zeka testi puanına yönelik histogram görselini gösterelim. SPSS programı ile hazırlanan veri görseli aşağıdaki gibidir:
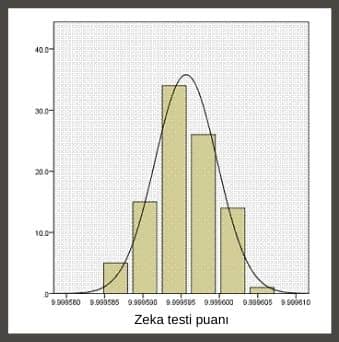
Görselimizde zeka puanlarının yaklaşık simetrik dağılım sergilediğini görebiliyoruz. Ancak puanların ortalama etrafında hafif sivri bir dağılım sergilediği de belli oluyor. Yani ortalamanın yakınında zeka puanlarında bir yoğunlaşma görebiliyoruz.
Aşağıdaki grafikte değişkenler arası ilişkilerin yönünü ve derecesini histogramlar ile beraber gösteren özel bir R grafiğini gösteriyoruz. Serpilme diyagramı, korelasyon katsayıları ve histogram grafiklerinin bir arada yer aldığı muazzam bir görsel şölen ile karşı karşıyayız.
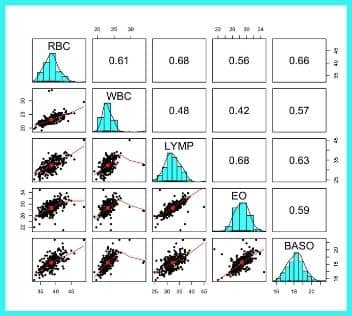
Bu grafikte bazı tıbbi ölçümler sonucu hesaplanmış kan parametreleri arasındaki ilişkileri net bir şekilde değerlendirebiliyoruz. Ayrıca bu noktalar üzerinden olası aykırı değer varlıklarını bile gözlemleme şansına sahibiz.
Şimdi sırada çok değişkenli istatistiksel veri analizine dair bir örnek daha verelim.
Açıklayıcı faktör analizinin veri görselleştirme teknikleri ile nasıl gösterileceğini inceleyelim. Bu grafik, bir bölgedeki suç verilerine ait açıklayıcı faktör analizi sonuçlarının görselleştirme sonuçlarını ifade ediyor. Açıklayıcı faktör analizine dair faktör sayıları, komünalite değerleri ve yüklerin yer aldığı özel bir veri görseli…
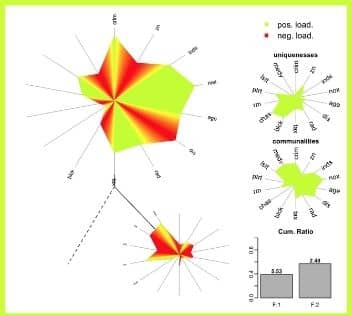
Bu grafiğe göre bulgularımızın iki faktör altında toplandığını; bazı soruların faktör yüklerinin daha yüksek olduğunu ve yüklerin işaretlerini gözlemleyebiliyoruz. Bu muhteşem grafik R programı ile çizilebiliyor.
Veri görselleştirme örneklerimizi artırmamız mümkün.
Veri Görselleştirme ve İstatistik Yazılımları
Şimdi veri görselleştirme tekniklerini hangi istatistik yazılımları ile uygulayabileceğimizi inceleyelim.
Bunun için hem ücretsiz, hem de ücretli seçeneklerimiz mevcut.
Ücretli istatistik yazılımları için en güçlü yazılımların başında R geliyor. Diğer ismi R-project.
R, veri görselleştirme alanında açık ara en güçlü istatistiksel analiz programı. İçerisinde en basit analizden en zor analize kadar onlarca görselleştirme yaklaşımı bulunuyor.
Diğer bir yazılım da son zamanlarda çok revaçta olan Python yazılımı. Python, kendi modülleri içerisinde hem açıklayıcı veri analizi, hem de veri madenciliği alanlarına yönelik veri görselleri sunuyor.
Ücretli araçlar arasında SPSS, Minitab, Stata gibi istatistik programlarını belirtebiliriz. Ancak bu programlar, veri görselleştirme kapasitesi açısından R ve Python’dan çok daha zayıf. Yine de temel görselleştirme sonuçlarını elde edebiliyoruz.
Bu yazımızda veri görselleştirme araçlarına kısaca değindik. Bu konu öylesine uzun ve derin ki, onlarca yazı yazsak bitiremeyiz. Gelecek yazılarımızda farklı istatistiksel analiz tekniklerine yönelik veri görselleştirme yaklaşımları üzerinde özelleşen bilgiler sunacağız.