
Ölçek Geçerliliği Kapsamında Uyum İyiliği İndeksleri
Sosyal bilimlerde anket çalışmaları kapsamında ölçek geliştirme veya ölçek uyarlamaya ilişkin sayısız bilimsel araştırmaya rastlayabiliriz. Anket çalışmalarında ölçek geçerliliği bulgularını değerlendirmek için, uyum iyiliği indekslerine ihtiyaç duyuyoruz.
Esasında ölçek geçerliliği için içerik, kapsam, yapı, kriter geçerliliği gibi farklı geçerlilik ölçüleri mevcut. Ancak en genel anlamda ölçek geçerliliği denildiğinde aklımıza gelen ilk istatistikler uyum iyiliği ölçüleridir.
Öncelikle ölçek geçerliliğini ölçümlemek için neler yapmamız gerektiğine kısaca göz atalım.
Anket çalışmalarımızda kullandığımız ölçeklerin alt boyutlarını belirledikten sonra, ilgili maddelerin belirlenmiş alt boyutlar altında geçerli bir şekilde toplanıp toplanmadığını incelememiz gerekir. Alt boyutlar kapsamında, ölçeğimize dair bir araştırma modeli kurgulamış oluruz.
Ölçek geçerliliği, araştırma modelimizin yapısı ile örneklem verilerimiz arasındaki uyumu ifade etmektedir. Özetle alt boyutlarımız ekseninde oluşturduğumuz ölçeğin, verilerimiz ile uyumlu olup olmadığını tespit etmemiz şarttır.
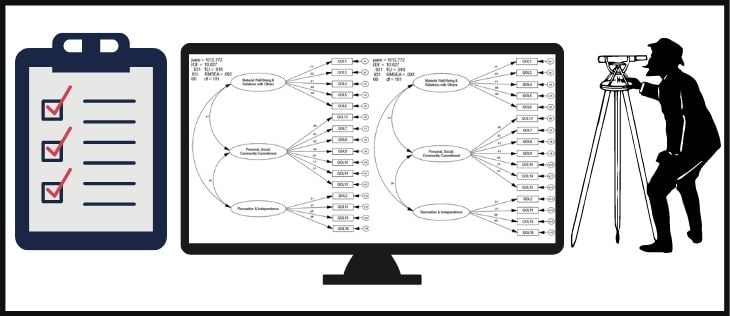
Ölçeğimizin geçerli bir ölçek olması için mutlaka ve mutlaka doğrulayıcı faktör analizi sonucunda elde edilen uyum iyiliği indeksleri göre uygun değerlere sahip olması gereklidir.
Uyum iyiliği indeksleri denildiğinde hangi değerleri düşünmeliyiz? Çok sayıda uyum iyiliği indeksi var. Aşağıdaki örnekleri sıralayabiliriz:
- (Ki-kare istatistiği)/(serbestlik derecesi)
- GFI
- AGFI
- CFI
- IFI
- RFI
- NFI
- NNFI
- TLI
- SRMR
- RMSEA
Yukarıda sıralamış olduğumuz her bir uyum iyiliği indeksinin kendisine göre belli sınırları var. Örneğin; RMSEA ve SRMR’nin düşük (0.10’un altında); CFI, GFI gibi indekslerin de 1’e yakın olmasını bekleriz.Bu sınırların dışında kalan ölçeklerin istatistiksel analiz bulguları açısından geçerli olduğunu söylemek çok zor.
Uyum indekslerinden ki-kare istatistiğine ait p-değerinin hata payımızından yüksek olmasını (p>0.05) isteriz. Neden? Sebebi basit. Bu durumda teorik model ile verimizin arasında anlamlı bir uyumun var olduğunu öngören Ho hipotezi reddedilemez.
Ancak bu olguya çok sık rastlayamıyoruz. Bilimsel araştırmalarımızda kurduğumuz modelin kovaryans matrisi ile verimize ait kovaryans matrisi arasında genelde istatistiksel olarak anlamlı fark bulunuyor (p<0.05).
Yine de modeli çöpe atmamak adına ikinci bir stratejiye sahibiz. Buna göre doğrulayıcı faktör analizi sonucunda elde edilen ki-kare istatistiğini modelin serbestlik derecesi sayısına bölüyoruz. Elde ettiğimiz bu değer de 5’in altında ise, kabul edilebilir bir uyuma eriştiğimizi söyleyebiliyoruz. Bazı kaynaklar (çok istisnai olmak kaydı ile) bu sınırı 10’a kadar çekebiliyor.
Maalesef, istatistiksel analiz danışmanlığı yapılmış olan bazı çalışmalarda bu indekslerin istenilen sınırlarda olmadığını gözlemliyoruz. Hakemler tarafından bu tür hataların gözden kaçırılması sonucunda, yanlış bilimsel sonuçlar içeren ölçek geçerliliği bulgularına rastlıyoruz.
Danışmanlık sürecinde doğrulayıcı faktör analizi yanlış uygulanmasına rağmen piyasa koşullarında yüksek istatistik analiz ücretlerinin alınması da son derece üzücü… İstatistik analiz ücretleri belirlenirken bu önemli analiz türünün de ciddi anlamda bir etki yarattığı düşünüldüğünde, oluşan etik dışı durum daha da belirgin hale geliyor.
Ölçek geliştirme ve uyarlama çalışmaları kapsamında yapılan hatalı çıkarımlar, bilimsel araştırmacılarımızın ismine gölge düşürebiliyor.
Özetle ölçek geçerlilik sınaması için en çok dikkat edilmesi gereken konuların başında referans sınırlarına uygun uyum iyiliği indekslerine erişmek geliyor. Özellikle CFI ve GFI değerlerinin 0.9’un üzerinde olmasını, RMSEA’nın da 0.10’un altında olmasını bekliyoruz.
Ancak yine de bazı kaynaklar referans değerlerin sınırlarına çok yakın sonuçlar elde ettiğimizde bunların kabul edilebileceğini ifade ediyorlar. Yine de ciddi bir eleştiriye maruz kalmamak adına, tüm indekslerin istenilen sınırlarda çıkması en iyisi.
Ölçek geçerliliği kapsamında uyum iyiliği indekslerini hesaplayabilmek için AMOS, Stata, R-project, Lisrel, M-plus gibi istatistik programlarını kullanabiliriz. Söz konusu istatistiksel analiz yazılımları kendi içerisinde farklı tahminciler ve farklı doğrulayıcı faktör analizi yaklaşımları barındırıyor.
Verilerimizin türüne uygun olmayan bir tahminci seçtiğimizde uyum indekslerimiz kötü çıkabiliyor. Örneğin; kategorik veriler için en çok olabilirlik tahmincisini uygularsak (ki AMOS ile hep bu yapılıyor) 0.90’un altında CFI, GFI değerlerine; 0.10’un üzerinde RMSEA, SRMR değerlerini bulmamız kaçınılmaz olabilir.
Ayrıca araştırma verilerimizin gözlem sayıları da düşük olduğunda istenmeyen sonuçlar ile karşılaşabiliriz. Bir diğer sorun da, modelimizde olması gerekenden daha fazla parametre ile çalıştığımızda kötü uyum indekslerini (yanlışlıkla) raporlayabiliyoruz.
Peki istenilen uyum iyiliği indekslerine erişemediğimiz durumlarda neler yapmalıyız? Neleri değiştirmemiz gerekiyor? Bu konuyu da gelecek yazılarımızda derinlemesine değerlendireceğiz.